
Si eres consultor SEO, estoy seguro de que habrás escuchado del JavaScript SEO, que es una parte de SEO técnico que permite que los sitios que estén desarrollados con JavaScript sean más fáciles de rastrear, renderizar e indexar. Si este no es el caso, mira esta excelente guía del equipo Onely.
Como resumen, hacer SEO en un sitio web desarrollado con JavaScript, normalmente significará que tienes que prestar atención a dos cosas:
- Asegúrate de que tanto los motores de búsqueda como los usuarios puedan ver las mismas cosas. Para alcanzar este objetivo, a menudo confiarás en el SSR (renderizado del lado del servidor) o el CSR (renderizado del lado del cliente) lo que podría hacer que se tengan colas de renderizado más largas.
- Asegurarse de que los componentes principales del SEO, como los enlaces, por ejemplo, no sean manipulados durante el proceso de renderizado.
Suena fácil, pero no siempre es tan fácil como suena. Además, existe un inconveniente específico que puede ser causado por los asistentes de JavaScript que me gustaría explicarte hoy. Porque no está bien documentado y potencialmente puede dañar a tu SEO. Y está vinculado con lo que se conoce como rehidratación de contenido.
¿Qué es la rehidratación de contenido?
La rehidratación de contenido es un proceso que ocurre cuando un sitio, hecho con un asistente de JavaScript, tal como Angular o React, actualiza de forma dinámica el contenido en la página sin necesidad de una recarga total de la página. Esto significa que cuando un usuario navega a una nueva página, la estructura principal de la página se carga primero, y después el contenido dinámico se carga en tiempo real, mejorando la velocidad de carga y la experiencia del usuario. Este proceso se llama rehidratación, porque esto “trae el contenido de vuelta a la vida” después de que ha sido cargado inicialmente. En Angular, esto se alcanza a través del uso de técnicas de renderizado de lado del servidor y de renderizado del lado del cliente, las cuales trabajan juntas para proveer una experiencia al usuario mucho más rápida y transparente.
¿Por qué utilizar la rehidratación en lugar de depender únicamente del SSR? Simple, porque esto reducirá el número de operaciones que pedirás hacer a tu servidor antes de enviar una respuesta al usuario, mientras te aseguras de que la aplicación es interactiva rápidamente.
Si te aseguras de que los componentes principales del HTML están incluidos en tu respuesta sin ser enviados al servidor, estaremos bien ¿No es así? Bien, pero no es tan simple. Déjame que te explique por qué.
¿Cuál es el inconveniente con la rehidratación de contenidos?
Por defecto, este comportamiento viene con una falla mayor.
Este añadirá un script a la respuesta enviada por tu servidor con todo el código requerido para hacer la aplicación dinámica. Este script podrá fácilmente representar más del 90% del total del tamaño del HTML, como el ejemplo mostrado debajo de esta herramienta. Sin embargo, 1,07MB (270kb comprimidos) no es algo que deba tener demasiado impacto, ¿No es así?
Yo solía creer esto. Pero hombre, no sabía lo equivocado que estaba.
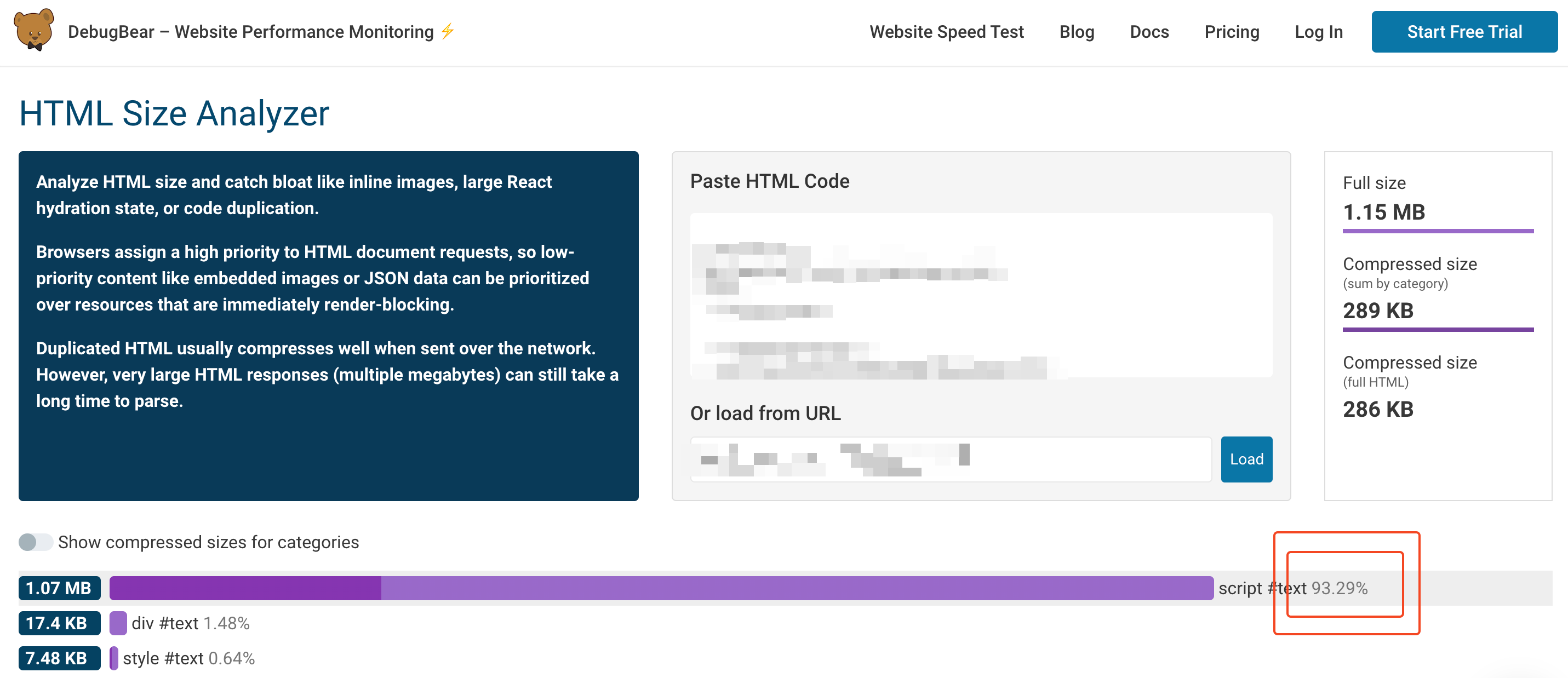
El problema no es el tamaño vinculado al script como tal, sino lo que esto significa para los motores de búsqueda.
Google explica claramente en su documentación cómo analiza un documento HTML. La conclusión es que una vez que se ha recibido la respuesta sin procesar, los archivos JavaScript son ejecutados para renderizar el HTML final. Mientras más código JS tengas, más tiempo tendrás que esperar para que la página se mueva de rastreada a indexada.
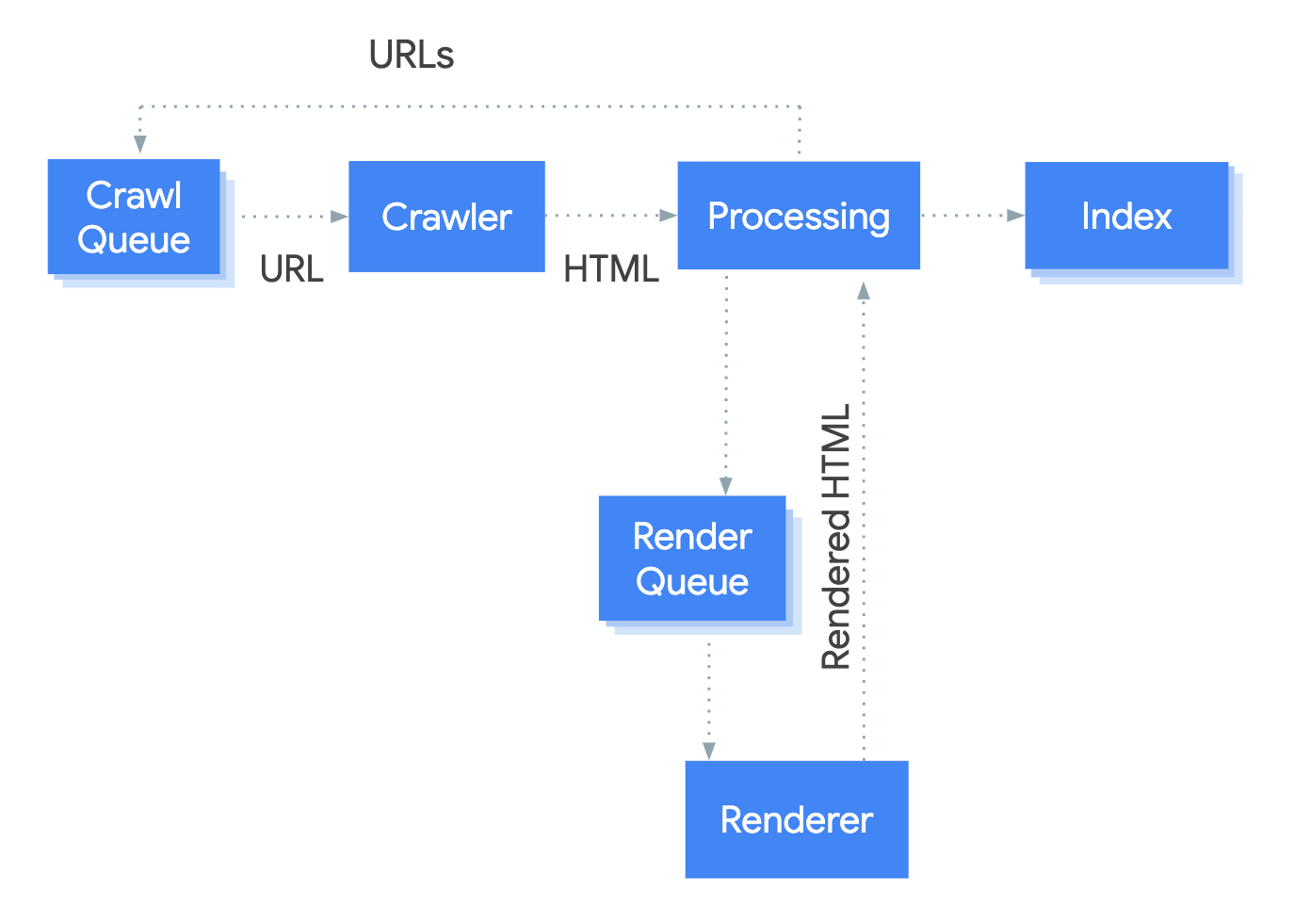
Si piensas desde la perspectiva de Google, esto tiene todo el sentido. De hecho, este es un comportamiento que recompensa a los sitios web que dependen en gran medida del SSR, lo que disminuye los costes operativos de Google, porque analizar JavaScript a gran escala puede ser muy costoso. Si utilizas la rehidratación, tu sitio necesitará tiempo para ser indexado, porque cada página pasará más tiempo en espera en la cola de renderizado.
¿Qué impacto puede tener durante una migración?
Suena aterrador, pero ¿Qué pasaría si te digo que es una situación que podría ir a peor? Imagina que estás migrando de un sitio web antiguo a un sitio desarrollado con JavaScript donde tendrás que cambiar la estructura de tus URL. No es una situación poco común si piensas al respecto.
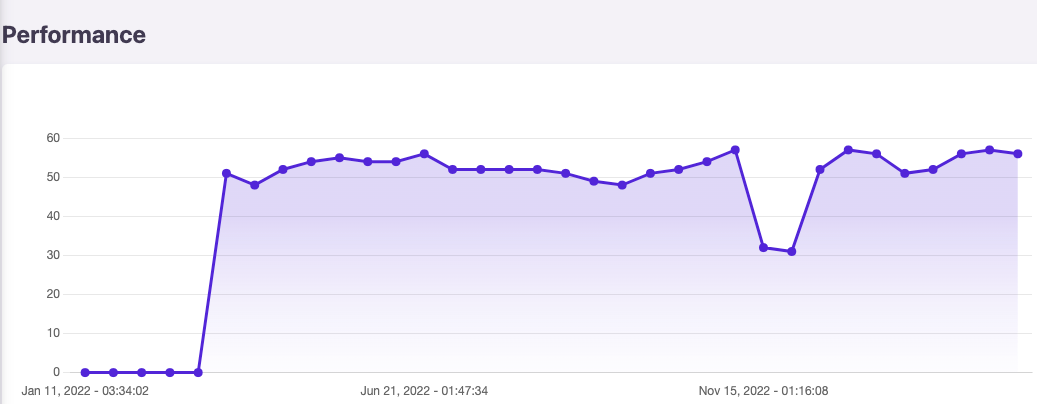
Bien, te enfrentarás a la siguiente situación con innumerables keywords: una drástica (pero temporal) caída, seguida por una nueva posición que es muy probable que sea inferior a la que tenías previamente, al menos en el corto plazo.
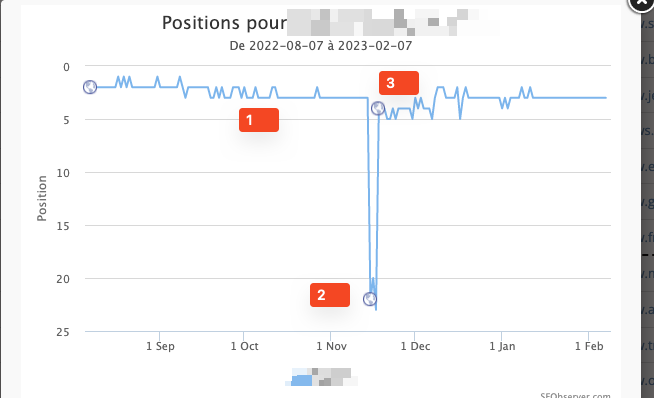
¿Por qué? Te preguntarás. Déjame explicártelo:
- Durante la fase 1 (en la captura anterior), observamos cambios que son completamente normales, como resultado, la página puede evolucionar diariamente.
- Durante la fase 2, un par de días después de que la redirección se implemente, la posición caerá drásticamente.
Lo raro acerca de esta fase, es que la URL que se posicionaba no será ni la URL vieja ni la nueva. Será otra diferente, que normalmente no coincide con la intención del usuario. Mi reacción inicial fue simple: Google está roto y no está asimilando las redirecciones tan bien como solía hacerlo.

Es más fácil culpar a un tercero cuando en realidad el problema viene de tu lado ¿Verdad? Lo que sucedía era realmente simple:
- Google detectó las 301 redirecciones y añadió las nuevas URL en la cola de rastreo.
- Debido a la rehidratación de contenido en las nuevas páginas, Google tardó una eternidad en procesar el contenido.
- En algún punto, eliminó la URL antigua de su índice (respetando las 301) pero como la nueva URL no había sido procesada aún, tomó la URL que coincidiera mejor por un momento.
- Cuando la nueva URL finalmente fue procesada, volvió (casi) a la misma posición.
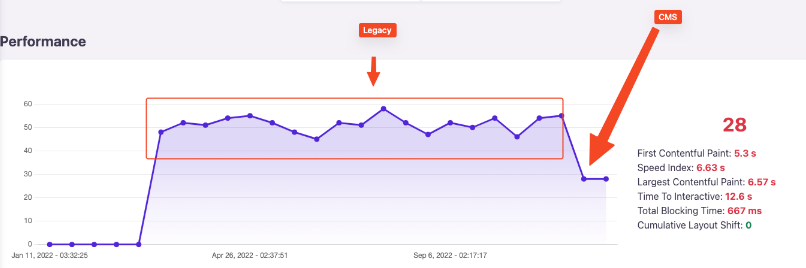
La diferencia para la posición entre la fase 2 y 3 se explica por la diferencia en la velocidad. Si bien CWV es un criterio de desempate, si la nueva página es significativamente más lenta que la anterior (la hidratación de contenido puede impactar todas las métricas del CWV excepto el CLS) y dados los recursos que Google tendrá que gastar en tu página, es muy probable que no recuperes tu posición inicial.
¿Cómo puedes resolverlo?
La rehidratación de contenido no es mala porque esto viene con muchas ventajas que ya te he explicado al principio de este artículo. Sin embargo, el script incluye un montón de información que no estás usando en tu aplicación. El truco consiste en optimizarlo pidiéndole a tu equipo que excluya la información que no se está utilizando.
¿Demasiado simple para ser verdad? Bien, esto es precisamente lo que hemos hecho aquí y después de la caída inicial, el tamaño del script se ha reducido en un 50-75% y el nivel de rendimiento ha vuelto a los niveles iniciales instantáneamente. Y las posiciones han empezado a volver a su nivel inicial justo después de esto.
Conclusión
Si bien tener un script enorme no afecta únicamente al sitio web creado con JavaScript, me he dado cuenta de que este problema afecta a muchos de ellos, incluso si no son detectados hasta que una migración ocurra. Al final del día, rara vez miraremos el tamaño total del HTML.
Si estás trabajando con un sitio web creado con JavaScript, tendrás que asegurarte de que conoces lo que es la rehidratación de contenido y explicar a tu equipo como se debe optimizar para evitar que tu SEO se rompa.